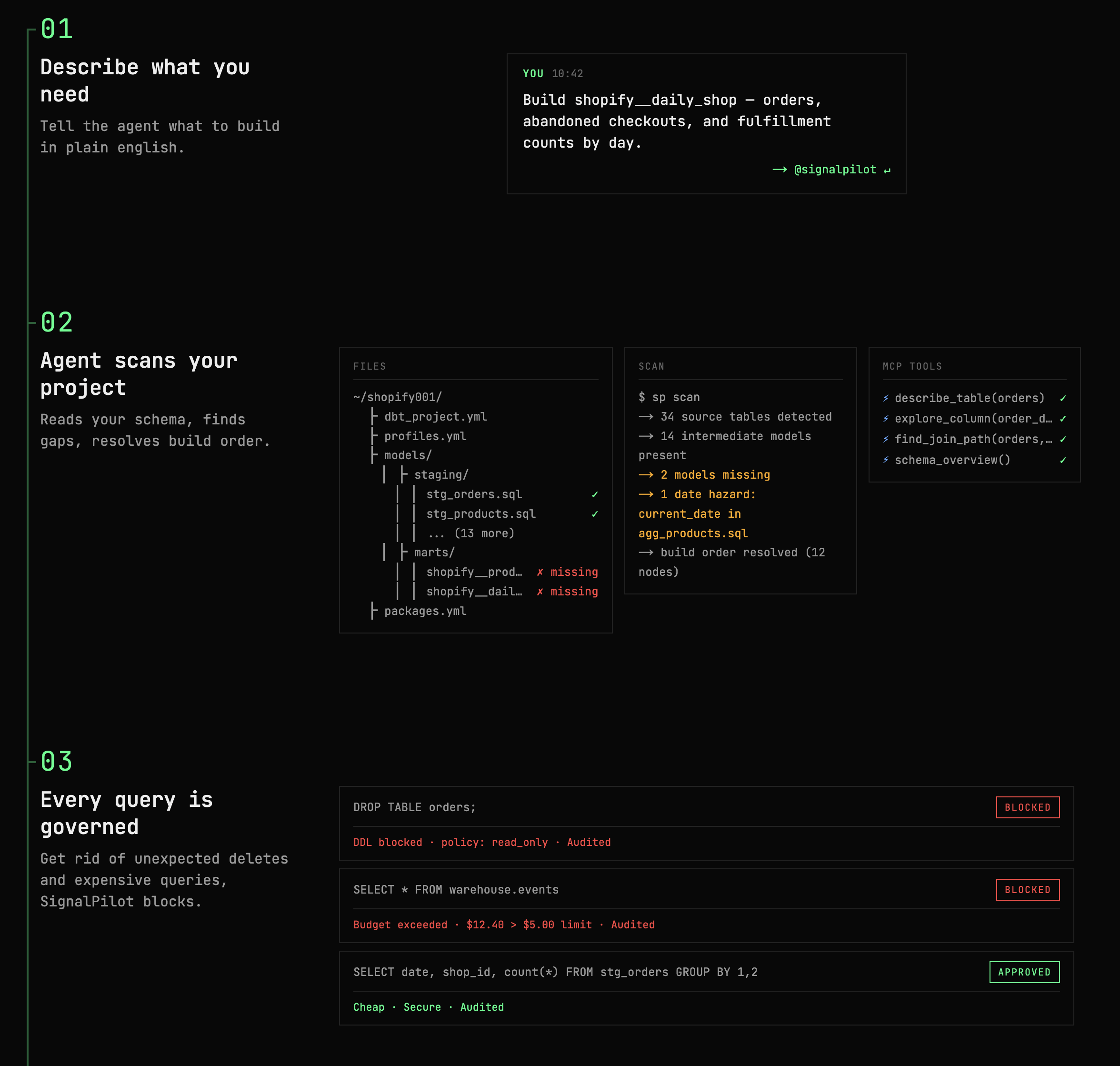
How We Beat JetBrains to #1 on the World's Hardest Data Benchmark
Tarik Moon
Today, we're thrilled to announce that SignalPilot has claimed the #1 spot on the Spider 2.0-DBT leaderboard—beating JetBrains' Databao by over 7 points. By solving dbt, the hardest problem in the transformation layer, we proved AI agents can be trusted with enterprise data pipelines when they have the right guardrails. Below, we break down the self-improving meta-harness that designed it and our vision for the autonomous data stack.
Spider 2.0-DBT isn't your typical text-to-SQL test. It is a grueling, 68-task code generation benchmark where agents are dropped into broken, real-world enterprise dbt repositories and told to fix them. To succeed, an agent must navigate complex SQL environments, understand the full data pipeline and context of a company, and process massive context windows.
For 11 months, no entry could cross the 50% success threshold.
Enter SignalPilot: The Governed Data Agent for dbt and beyond
Testing against the Spider 2.0-DBT benchmark proved a harsh reality: most AI coding agents fail at data engineering because they treat the warehouse like a text box. They guess at column names, silently fan-out revenue numbers, and occasionally try to DROP production tables.
"Please don't drop tables" in a system prompt is a wish, not a security control
 SignalPilot Architecture
SignalPilot Architecture
SignalPilot succeeded where others failed because we designed it with absolute, mathematically verifiable guardrails, with a predictable yet robust workflow. It is built on three core pillars:
1. The Governance Gateway
SignalPilot sits between the AI agent and your database. Every query passes through a fail-closed gateway that makes destructive mistakes physically impossible. Some of the notable governance measures are:
- AST Validation: DDL (
DROP,ALTER) and DML (INSERT,DELETE) are blocked at the wire. - LIMIT Injected & Read-Only: Every query is automatically bounded.
- PII Redaction & Audit Log: Full query lineage, cost tracking, and automatic PII masking.
2. The 7-Check Verification Protocol
Instead of relying on LLM vibes, SignalPilot uses a specialized subagent architecture to guarantee correctness.
The Main agent uses tools like dbt_project_map and explore_column to understand your schema and dependencies before writing the model. Then, a dedicated Verifier subagent rigorously audits the build using a deterministic 7-check protocol:
- Model Existence: Verifies the model was actually materialized.
- Column Schema: Compares output columns against the YML contract.
- Row Count: Validates against the reference snapshot.
- Fan-Out Detection: Runs
analyze_grainto catch silent metric inflation. - Cardinality Audit: Checks upstream sources for over-filtering.
- Value Spot-Check: Validates sample rows against reference data.
- Table Name Verification: Ensures all expected names exist.
If any check fails, the Main agent or a targeted Quick-Fix agent jumps back in to repair the SQL before a single PR is opened.
3. The 40-Tool MCP Ecosystem
You can't solve enterprise data problems with just a "run_sql" tool. SignalPilot provides its agents with a massive surface area of 40 specialized MCP tools, organized into six capability tiers:
- Data Exploration (9 tools):
explore_table,explore_column,schema_diffand more. The agent can deep-dive into distinct values, NULL stats, and foreign key relationships before writing code. - Query Intelligence (11 tools):
validate_sql,explain_query,find_join_path,compare_join_types. The agent can dry-run queries to check execution plans and row estimates without spending budget. - dbt Project Intelligence (6 tools):
dbt_project_map,dbt_error_parser,fix_date_spine_hazards. The agent reads your YML, parses raw dbt errors into structured fixes, and auto-patches non-determinism. - Model Verification (4 tools):
analyze_grain,audit_model_sourcesand more to mathematically prove correctness. - Compute & Infrastructure (7 tools):
execute_code(runs Python 3.12 in isolated gVisor sandboxes), plus connection health and cache status telemetry. - Project Management (3 tools): Standard dbt project scaffolding.
To do a deeper dive, you can clone and star our open source repo here: GitHub
The Secret Weapon: AutoFyn Meta Harness
So how did a small team design an agent architecture capable of mastering this massive ecosystem?
We knew that manually tweaking system prompts wasn't going to beat billion-dollar engineering orgs. To solve the hardest benchmark in data, we built the machine that builds the machine.
Meet AutoFyn: a long-running agent optimizer meta-harness.
Instead of writing static code, we used AutoFyn to run Claude Opus (and to save cost—Claude Sonnet) in self-improving loops against real codebases. We gave it a repository, a task, and a long time horizon, structured around a few core mechanics:
- Sandboxed execution: In each round, Claude ran in a fresh, isolated Docker container.
- Persistent memory: Its knowledge persisted externally across rounds through git history.
- Continuous optimization: The agent generated detailed round reports and a "lessons learned" file to compound its reasoning over time.
AutoFyn didn't just prevent the agent from degrading over time—it forced it to compound its knowledge and optimize its own architecture.
To give you a sense of how powerful this harness is: AutoFyn autonomously discovered 26 vulnerabilities across top open-source projects. We can't disclose details yet—we're coordinating disclosure with the affected teams.
AutoFyn vs. Ralph: Ralph is a well-known open-source harness from Geoffrey Huntley that runs a single agent in a simple while loop—point it at a repo, let it iterate. It's elegant and effective for bounded tasks. But when we pushed this pattern against the Spider 2.0-DBT benchmark, AutoFyn discovered something critical: a massive, monolithic agent degrades in reasoning over long horizons. Context rot compounds, and the agent starts making worse decisions the longer it runs. AutoFyn optimized toward a multi-agent setup with specialized sub-agents handing off bounded contexts—which performed exponentially better.
We pointed AutoFyn at the Spider 2.0-DBT benchmark. Through thousands of self-improving loops, it learned exactly why standard agents fail at data engineering, and it generated the optimal architecture we just showed you: SignalPilot.
We are building in public and with the open source community. We will share more as AutoFyn matures.
Towards the Autonomous Data Stack
We aren't stopping at copilot mode. We are building the vendor-neutral Autonomous Data Stack:
- Compounding Agents: SignalPilot isn't static. It feeds every passing test, failed verification, and manual fix back into its skills and prompt scaffolding. It self-improves as you use it daily, compounding its knowledge of your unique business logic and semantic grain.
- Self-Healing Pipelines: SignalPilot will live in your CI/CD, patching dbt models when upstream schema migrations land—before PagerDuty fires.
- Ambient Agents: SignalPilot will run continuously in isolated gVisor microVMs, monitoring metrics and dropping verified insights directly into Slack for non-technical users and leaders who just want to trust their data.
Try it today
SignalPilot is open-source and you can install it locally in 1 minute:
1 - Start SignalPilot
git clone https://github.com/SignalPilot-Labs/signalpilot.git
cd signalpilot && docker compose up -d
2 - Add to Claude Code
/plugin marketplace add ./plugin
/plugin install signalpilot-dbt@signalpilot
Star the Repo | Join the Slack Community
We built SignalPilot because the data stack deserves agents that are trusted by default, not trusted by accident. If that mission resonates—whether you're a data engineer tired of babysitting brittle pipelines, a founder betting your company on dbt, or an investor looking at the next layer of the AI-native data stack—we want to hear from you.
Star the repo. Break the agent. Tell us what's missing.
The autonomous data stack is being built in public, and the next 12 months are going to be wild.