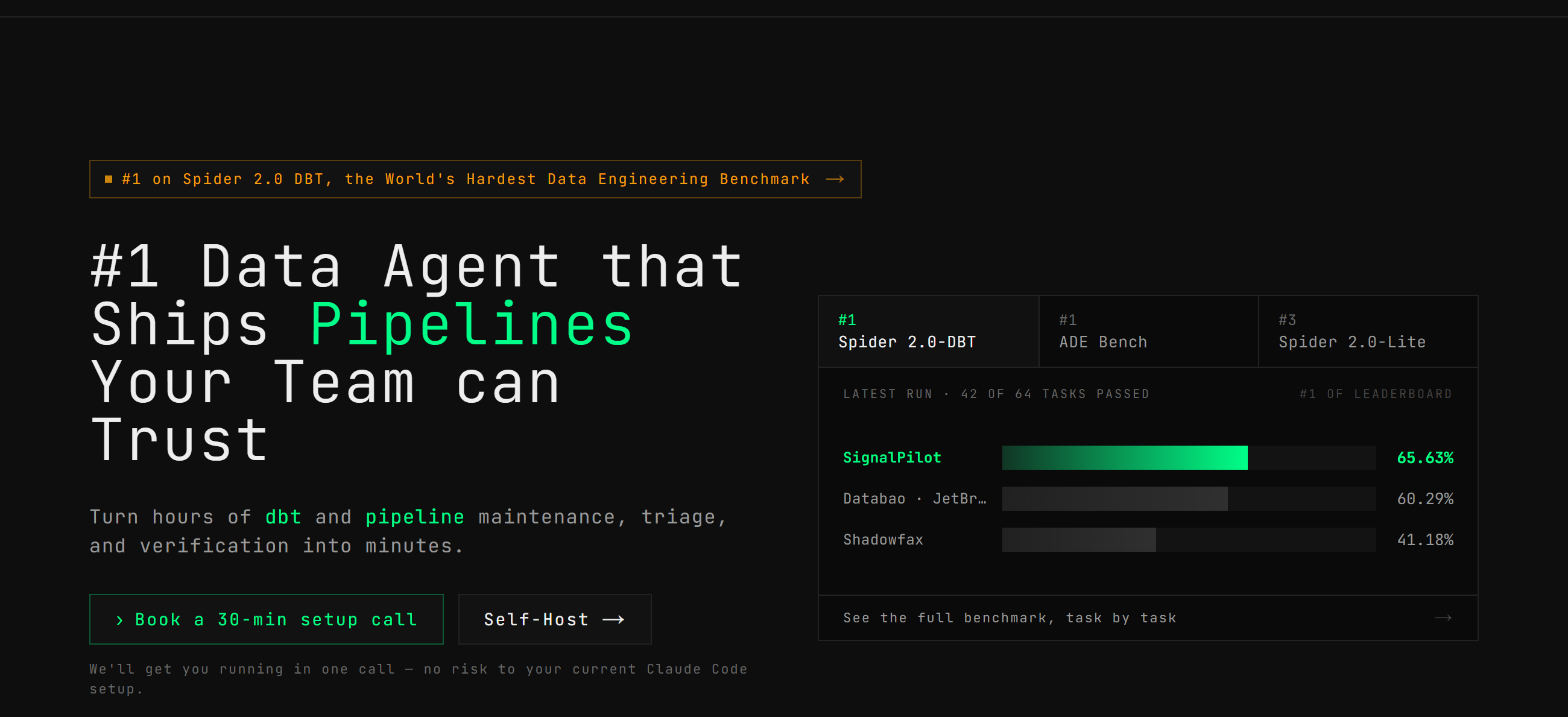
How Claude Code + SignalPilot Builds Production-Grade dbt Models
Luiz Fernando

The Experiment
Starting point: An empty directory and a Postgres container.
Goal: Build a complete, production-grade dbt project with proper layering, testing, documentation, and validation.
Tools: Claude Code (AI pair programmer) + SignalPilot MCP (governed database access).
Constraint: Ship it in one session.
The Full Prompt
Here's the actual prompt that kicked everything off:
Build a full dbt project against the signalpilot_ops database (port 5602).
35K rows across 10 tables — multi-tenant SaaS operational data.
Full staging → intermediate → marts architecture, with tests.
That's it. One prompt. Let's trace what happened.
Phase 1: Environment Setup (2 minutes)
Claude Code handled the full toolchain:
- Python venv creation — Created
.venvwith Python 3.12 (dbt doesn't support 3.14 yet — Claude detected the compatibility issue and downgraded automatically) - dbt installation —
pip install dbt-core dbt-postgres - Project scaffold —
dbt init signalpilot_ops - Connection config — Inspected the Docker container to get credentials (
dbt_user/dbt_pass), wroteprofiles.yml
Key moment: The first dbt debug failed with password authentication failed for user "postgres". Claude Code ran docker inspect to find the actual credentials, fixed the profile, and re-tested. No human intervention.
Phase 2: Schema Discovery via SignalPilot (1 minute)
Two MCP calls:
list_database_connections() → "SignalPilot-Ops (postgres) — host.docker.internal:5602"
list_tables("SignalPilot-Ops") → 10 tables with full column lists
Then 6 parallel query_database calls to profile the data:
- All 12 orgs with their BYOK and creation dates
- Audit log samples showing agent attribution and blocked queries
- Connection details showing 6 database types
- Health events with latency patterns
- Budget sessions with spend tracking
- Settings JSON with compliance config
Then 4 more queries for aggregate patterns:
- Per-org query volumes and block rates
- Agent types: claude-code, cursor, dbt-agent
- Connection health tiers (64%–100% uptime)
- Budget utilization (govcloud $0.22/session vs startup $3.45/session)
Total: 12 governed SQL queries. Full database understanding in under a minute.
Phase 3: Model Architecture (5 minutes)
Claude Code built the entire 3-layer structure:
sources.yml
10 source table declarations with descriptions.
Staging Layer (9 models)
One per source table. Each model:
- Renames
id→{entity}_idfor clarity - Casts
to_timestamp(epoch)for all timestamp columns - Renames ambiguous columns (
tables→queried_tables) - Extracts JSON fields (
settings_json::jsonb->>'pii_masking')
Intermediate Layer (4 models)
- int_org_profiles — Joins orgs + settings + connection counts + project counts
- int_connection_health — Aggregates health events, classifies into tiers
- int_query_activity — Daily query aggregates per user/agent/connection
- int_budget_utilization — Budget vs spend with utilization percentages
Marts Layer (3 models)
- org_dashboard — Joins all intermediates into an executive org view
- security_posture — Scores each org's security (high/medium/low)
- agent_analytics — AI agent query attribution and cost analysis
Test Declarations
25 tests across 2 schema.yml files:
unique+not_nullon every primary keyrelationshipsfor foreign key integrityaccepted_valuesfor enum columns
Phase 4: Build and Fix (2 minutes)
First dbt run: 14/16 pass, 1 error, 1 skip.
The error: stg_api_keys failed because gateway_api_keys.created_at is VARCHAR storing epoch numbers, not DOUBLE PRECISION. Claude Code:
- Ran a diagnostic query through SignalPilot:
SELECT created_at, pg_typeof(created_at) FROM gateway_api_keys LIMIT 3 - Got:
'1735689600' | character varying - Fixed the model:
to_timestamp(created_at::double precision)
Second dbt run: 16/16 pass.
Then dbt test: 25/25 pass.
Phase 5: Validation via SignalPilot (1 minute)
Three validation queries through the governed MCP:
-- Org dashboard
SELECT org_id, avg_uptime_pct, total_queries, total_query_cost_usd
FROM public_marts.org_dashboard ORDER BY total_queries DESC
-- Security posture
SELECT org_id, security_score, pii_masking_mode, byok_enabled
FROM public_marts.security_posture ORDER BY security_score DESC
-- Agent analytics
SELECT agent_id, org_id, total_queries, block_rate_pct, total_cost_usd
FROM public_marts.agent_analytics ORDER BY total_queries DESC
All results verified: security scores correctly reflect compliance patterns, health tiers match expected uptime ranges, agent attribution tracks all three AI tools.
What Makes This "Production-Grade"
1. Proper Layering
Not everything dumped into one folder. Sources → Staging → Intermediate → Marts with clear separation of concerns.
2. Materialization Strategy
- Staging + Intermediate = views (no storage cost, always fresh)
- Marts = tables (pre-computed for fast dashboard queries)
3. Testing
25 tests covering:
- Primary key uniqueness and null checks
- Foreign key referential integrity
- Enum value validation
4. Documentation
Every model and source has descriptions. dbt docs generate produces a full documentation site with lineage DAG.
5. Error Handling
Type mismatches caught and fixed through the same governed query tool. No manual debugging cycle.
The Architecture
┌──────────────────────────────────────────────────────────────┐
│ Claude Code │
│ (AI pair programmer — writes models, fixes errors, tests) │
├──────────────────────────────────────────────────────────────┤
│ SignalPilot MCP │
│ (Governed database access — read-only, audited, limited) │
├──────────────────────────────────────────────────────────────┤
│ dbt Core │
│ (Build engine — compiles SQL, manages DAG, runs tests) │
├──────────────────────────────────────────────────────────────┤
│ PostgreSQL │
│ (Source database — 35K rows, 10 tables, 12 orgs) │
└──────────────────────────────────────────────────────────────┘
The flow:
- Claude Code explores the database through SignalPilot (governed)
- Claude Code writes dbt models based on what it discovers
- dbt compiles and runs the models against Postgres
- Claude Code validates output through SignalPilot (governed)
- Claude Code runs dbt tests to verify data quality
Get the Code
The full project is open source:
github.com/SignalPilot-Labs/signalpilot-web-dbt
Clone it and follow the instructions below to run it locally.
Reproducing This
Note: We used Claude Code here, but SignalPilot works with any MCP-compatible client — Cursor, Windsurf, Codex, Cline, or any agent that speaks the protocol.
1. Connect SignalPilot to your coding agent
claude mcp add --transport http signalpilot https://gateway.signalpilot.ai/mcp
2. Point it at your database
Register your database connection in the SignalPilot dashboard. Postgres, Snowflake, BigQuery, Redshift, ClickHouse, and DuckDB are supported.
3. Build
Point your agent at the database and tell it to build a dbt project with staging, intermediate, and marts layers. It will use SignalPilot's MCP tools to explore the schema, profile data, write models, and validate output — all governed.
The Takeaway
This isn't about replacing analytics engineers. It's about collapsing the iteration loop:
| Traditional | Claude Code + SignalPilot |
|---|---|
| Open SQL client, explore schema | One MCP call: list_tables |
| Copy schema to ChatGPT, ask for model | AI reads schema directly, writes model |
Run dbt run, check terminal | AI runs dbt, reads errors, fixes them |
| Open SQL client, validate output | AI queries marts through governed MCP |
| Write tests manually | AI writes tests alongside models |
From 4 context switches per iteration to zero. The human's job shifts from typing to reviewing — which is where the judgment should be anyway.
16 models. 25 tests. One conversation.
Built with Claude Code + SignalPilot MCP.